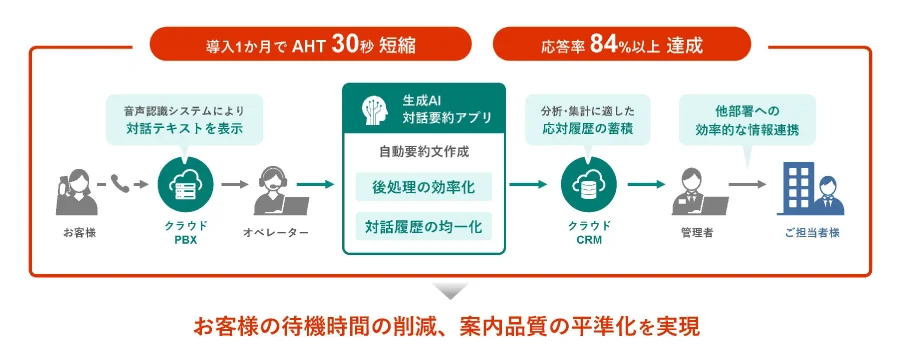
AIスタートアップのNABLAS(東京都文京区、中山 浩太郎代表取締役所長)は2024年8月、Googleが開発した音声生成モデル「SoundStorm」をベースに、日本語に対応した音声生成モデルを開発した。これにより、数秒の対話データのみで、話者の声の抑揚や特徴を忠実に模した、日本語の音声生成が可能になる。
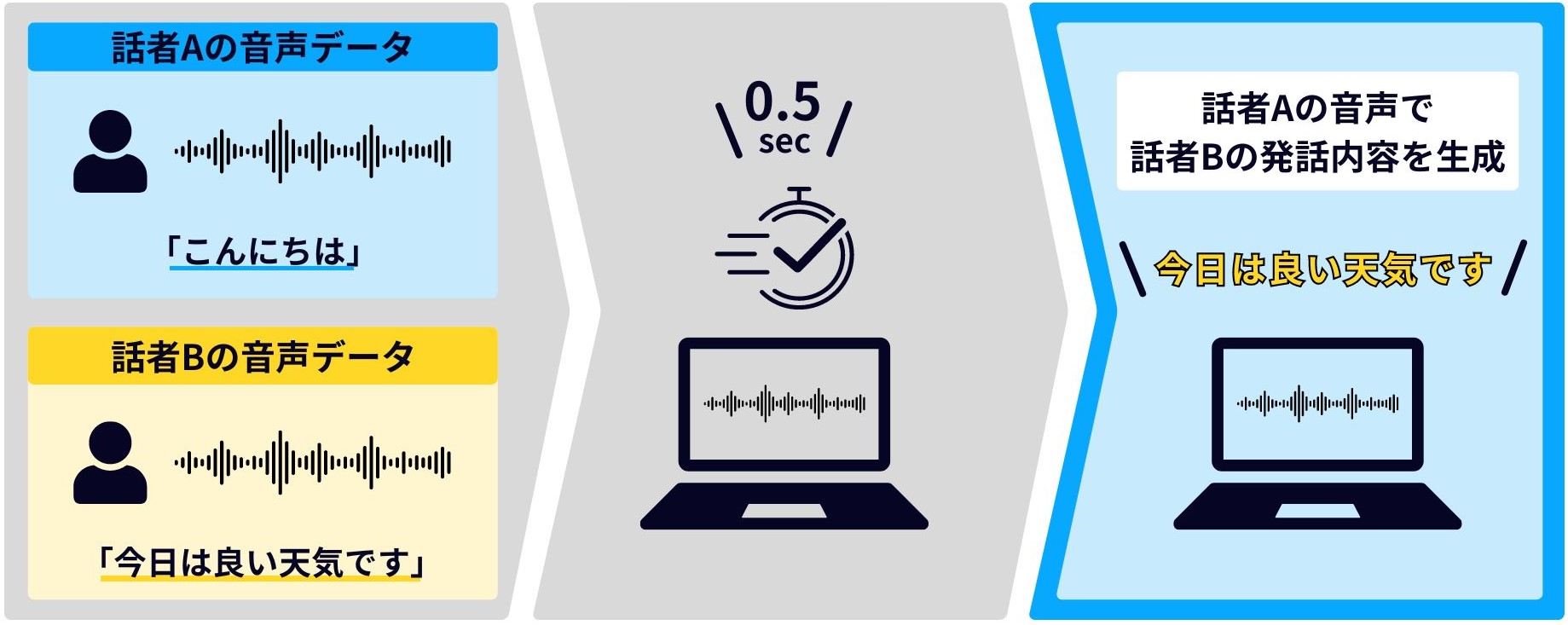
例えば、数秒の話者Aの音声データと、「今日は良い天気です」と発話する話者Bの音声データを活用して、話者Aの音声で「今日は良い天気です」と発話する音声データを生成できる(図1)。発話困難者の支援や、カスタマーサポートでは顧客の音声を、感情を抑えたものに変換するといった仕組みでオペレータの心的負担を軽減するなどの活用シーンを想定している。
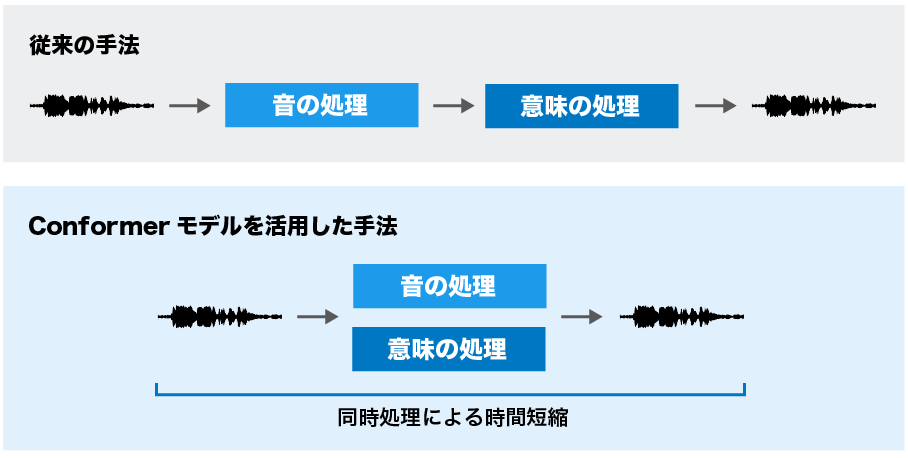
同モデルは、SoundStorm内部に、Googleが開発した、テキストの全体的な文脈と局所的な文脈を同時に捉えることができる「Conformerモデル」をベースに開発しており、音声生成のクオリティとスピードを追求している(図2)。
今後は、音声変換やテキストの読み上げ、リアルタイムでの対話翻訳などへの実装を進めていく。
2024年09月03日 11時49分 公開
2024年09月03日 11時49分 更新