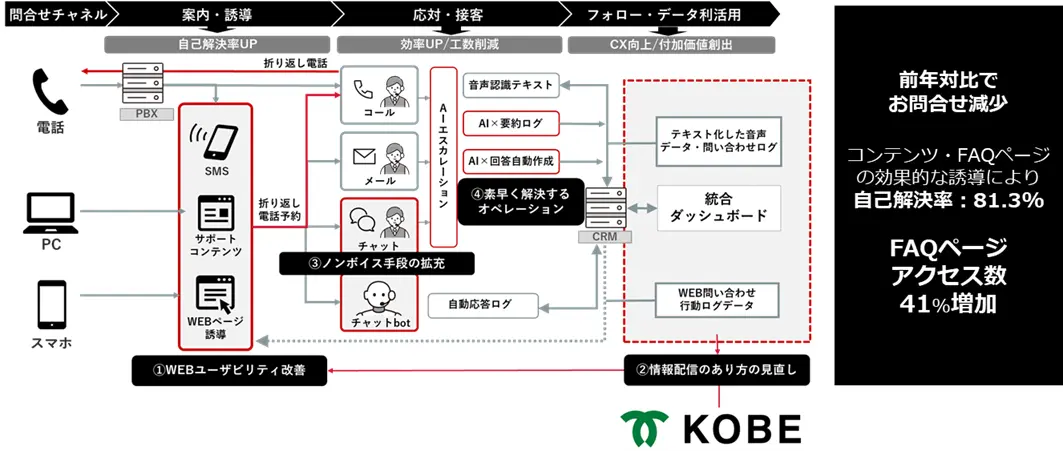
NTTは、大規模言語モデル(LLM)を用いた問い合わせ自動応答において、プライバシー保護と応答精度を両立する手法を確立したと発表。問い合わせ応答業務では、過去の利用者の入力と応答のペアを活用する「文脈内学習(In-Context Learning:ICL)」が注目されている。しかし、過去の問い合わせ内容が別の利用者への応答にも反映されるため、新たな利用者が似た問い合わせを意図的に繰り返すことで、「特定の問い合わせがあったか」などの情報が、第三者に漏洩するリスクがある(図1a)。その解消のために応用されている差分プライバシー(構造化されたデータベースに対する統計的処理の出力が、「特定のレコードの有無に関わらず統計的に区別できないのであれば安全である」という識別困難性に基づくプライバシー保護の強度を定量化する指標)に基づく手法である「差分プライベートなICL(DP-ICL)」では、ノイズ付与による精度低下が課題だった(図1b)。NTTは世界で初めてノイズの影響を理論的に分析し、その改善策として「Plausible Token Amplification(PTA)」を提案した。
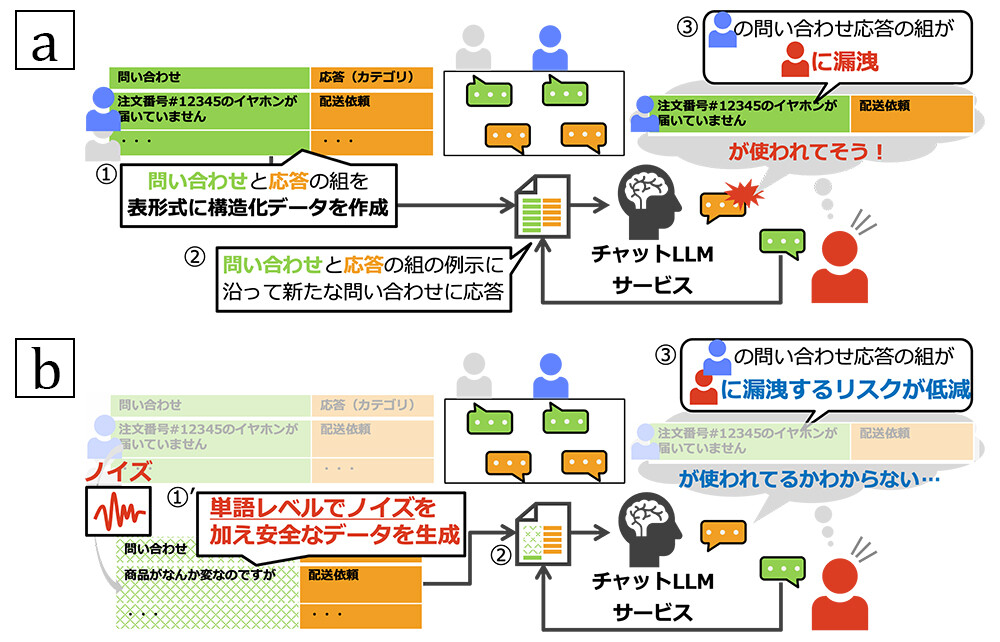
NTTはDP-ICLにおける精度低下の要因をベイズ推論の枠組みで解析、以下を明らかにした。
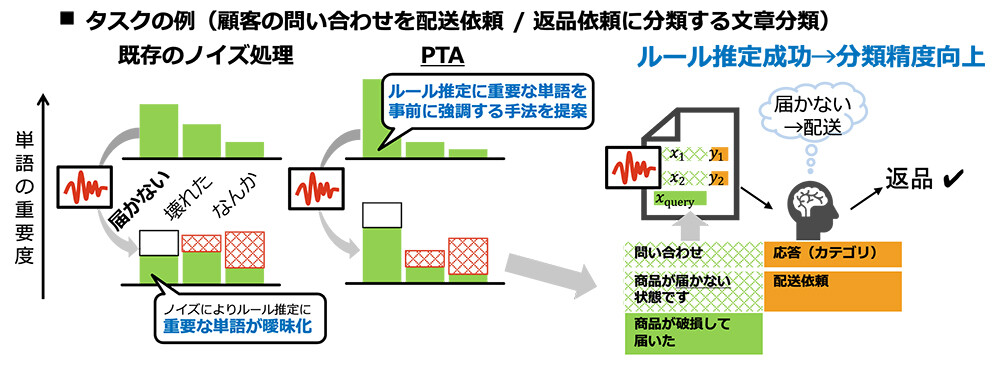
•知見1:無関係な単語を生成候補からあらかじめ除外することで、ノイズの悪影響を抑制できることを理論的に示した
•知見2:ルールを特徴づける重要語の生成確率を意図的に高めることで、ノイズ下でも正しい応答傾向を高精度に推定できる
PTAは、無関係な語の生成を抑えながら、ルールを特徴づける単語の生成確率を高めた上で、ノイズを加えて安全な例題を生成。ノイズが加えて生成された安全な例題からでもLLMが正しいルールを高精度に推定することができ、応答精度と安全性の両立が実現する。
ニュース記事分類タスクにおいてPTAを適用した結果、既存DP-ICLよりも精度が大幅に改善し、ノイズを加えない従来ICLと同等水準の性能を達成。安全性と実用性の両立が確認された。
PTAは、問い合わせ履歴が使われたかどうかの推測を困難にするため、医療・金融・行政といった高い安全性が求められる分野での活用が期待される。特に、コールセンターにおけるチャットボットなどでも、個人情報の統計的漏洩リスクを抑制しつつ精度の高い応答を実現できる点が注目されそうだ。
2025年09月28日 12時10分 公開
2025年09月28日 12時10分 更新