ELYZA、商用利用可能な130億パラメータの日本語LLMを一般公開
AIベンダーのELYZA(東京都文京区、曽根岡侑也代表取締役)は2023年12月、商用利用可能なトークン数130億パラメータの日本語LLM「ELYZA-japanese-Llama-2-13b」を一般公開した。
今回公開したモデルは、「ELYZA-japanese-Llama-2-13b」、「ELYZA-japanese-Llama-2-13b-instruct」および「ELYZA-japanese-Llama-2-13b-fast / ELYZA-japanese-Llama-2-13b-fast-instruct」の3種類。これらのモデルは、2023年8月に公開した「ELYZA-japanese-Llama-2-7b」と同じく、米Meta Platformsが提供する大規模言語モデル「Llama 2」に日本語テキストを追加事前学習し、ELYZA独自のチューニングを行った。

図1:自律神経・副交感神経に関する質問例
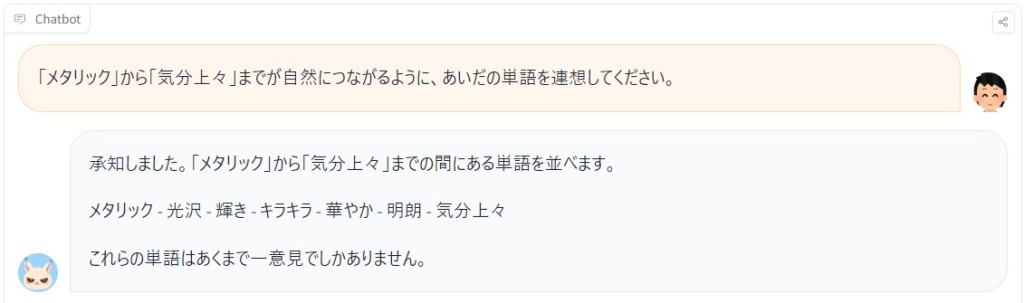
図2:「メタリック」から「気分上々」までの単語連想を指示する質問例
新モデルは前回発表した「ELYZA-japanese-Llama-2-7b」と比較して、パラメータ数が130億まで増加したことに加え、事前学習に使用するデータを増強したことで、日本語の性能が向上し高速化を実現。具体的には、回答の出力精度に関して箇条書き形式での説明にとどまらず、より順序立てた説明が可能になった(図1参照)。また、指定した2単語間をつなぐような単語を連想された質問においても、極めて自然な単語の連想ができるようになった(図2参照)。
今回発表したモデルは、AIプラットフォーム共有サイト「Hugging Face Hub」にて公開中で、ライブラリ上から利用可能としている。
<関連サイト>
・「ELYZA-japanese-Llama-2-13b-instruct」デモサイト
(URL:https://huggingface.co/spaces/elyza/ELYZA-japanese-Llama-2-13b-instruct-demo)